torsdag 17. desember 2015 Common Lisp Julekalender Samtidighet
I denne bloggposten vil jeg demonstrere ulike teknikker for parallellisering i Common Lisp, jeg vil se på channels, futures, og parallelle versjoner av normale listeoperasjoner. Jeg vil også komme borti hvordan man kan distribuere arbeidsmengden over flere maskiner.
I luke 16 i Knowit sin julekalender skulle de ha oss til å telle forekomster av sifferet "2" i serien fra og med 0 til og med 12345678987654321. Det nyttet ikke å brute force' seg frem til svaret her - jeg skal innrømme at det var mitt første forsøk, men det ville ta aaaaalt for lang tid. Dermed ble det litt googling, og jeg kom frem til en matematisk løsning:
(defun ->int (x)
(with-input-from-string (in x)
(read in)))
(defun count-twos-by-math (&optional (n "12345678987654321"))
(if (= 1 (length n))
(if (>= (->int n) 2) 1 0)
(let ((magnitude (1- (length n)))
( leading (->int (subseq n 0 1)))
( rest (subseq n 1)))
(let ((twos (* leading magnitude
(expt 10 (1- magnitude)))))
(cond
((= leading 2) (incf twos (1+ (->int rest))))
((> leading 2) (incf twos (expt 10 magnitude))))
(+ twos (count-twos-by-math rest))))))
Men det er ikke dette denne blogposten skal handle om. Gitt at tallrekken man skulle søke i ikke hadde vært så forferdelig lang kunne jo brute force ha vært en grei strategi...
... og da kunne jeg brukt denne enkle løsningen:
(defun count-twos (start end)
(loop for n from start to end
for n-string = (format nil "~A" n)
summing (count #\2 n-string)))
(count-twos 0 10000) kjører for eksempel (på min maskin) på 0,003 sekunder. Øker vi øvre skranke til én million får vi en kjøretid på drøye 0,6 sekunder, og en serie på 100 millioner tall prosesseres på 66,9 sekunder.
Men så kom jeg til å tenke på at jeg jo har en Intel Core i7-3820QM CPU, og den har fire kjerner. Min brute forcing utnytter bare én av dem. 66,9 sekunder er jo lenge å vente, men hvordan kan vi parallellisere dette?
Denne oppgaven er det vi kaller et pinlig parallelliserbart problem; det er enkelt å dele den opp i flere oppgaver. Derfor begynte jeg å lete etter hvordan man gjør sånt i Common Lisp.
Common Lisp har ulike pakker for parallellisering, men ett som virker populært er lparallel. Som vanlig enkelt å installere med quicklisp:
(ql:quickload :lparallel)
(use-package :lparallel)
Før man kan bruke funksjonene det tilbyr må man opprette en kjerne som spesifiserer hvor mange tråder man vil ha. Det fungerer som regel greit å bruke antall CPU-kjerner til dette:
(setf *kernel* (make-kernel 4))
Om du glemmer dette steget så gir lparallel deg en fin feilmelding som forteller hva du skal gjøre.
(Jeg har fire kjerner, men åtte logiske kjerner, eller hva det nå heter. Jeg eksperimenterte med ulike settings, men alt mellom 4 og 8 så ut til å fungere like bra.)
Første steg for å paralellprosessere tallrekken er å splitte opp oppgaven. I mitt tilfelle ønsker jeg da altså fire rekker i stedet for én. Det er mulig det finnes smartere måter å gjøre dette på, men jeg laget i alle fall denne hjelpefunksjonen:
(defun split-range (pieces start end)
(let* ((elm-count (- end start))
(piece-count (floor (/ elm-count pieces))))
(loop for x from 0 to (1- pieces)
for pstart = (+ start (* x piece-count))
for pend = (+ pstart (if (= x (1- pieces))
(- end pstart)
(1- piece-count)))
collect (cons pstart pend))))
Om vi nå ber om (split-range 4 0 100000000) så får vi:
((0 . 24999999)
(25000000 . 49999999)
(50000000 . 74999999)
(75000000 . 100000000))
En av tingene lparallel tilbyr er såkalte channels (kanaler). Dette er et objekt du oppretter, og som du kan sende jobber til. lparallel tar seg av å utføre jobbene med en tilgjengelig worker. Siden kan man be kanalen om å få resultatet tilbake.
Dette er en modell for samtidighet som man finner i flere og flere språk for tiden, og var for eksempel noe av det som gjorde Go så populært.
Vi bruker make-channel til å opprette en ny kanal:
(defvar foo (make-channel))
Vi kan så sende kanalen en jobb i form av en funksjon og noen argumenter. I dette tilfelle sender jeg funksjonen pluss og argumentene 1, 2, 3 og 4:
(submit-task foo #'+ 1 2 3 4)
Til slutt henter vi resultatet:
(receive-result foo)
==> 10
Vi kan nå lage en variant av count-twos som først splitter opp problemet i fire deler, og så oppretter en kanal for prosessering av hver del. Vi ber hver kanal om å prosessere sin del vha. submit-task, henter resultatet fra hver kanal, og summerer tilslutt sammen.
Her er en løsning som fungerer:
(use-package :cl-arrows)
(defun count-twos-channels (start end &key (threads 4))
(let ((pieces (split-range threads start end))
(channels (loop for i from 1 to threads
collect (make-channel))))
(->>
(mapc (lambda (channel piece)
(submit-task channel
#'count-twos
(car piece)
(cdr piece)))
channels
pieces)
(mapcar #'receive-result)
(reduce #'+))))
Tips: mapc er en variant av map som jeg ikke bruker så ofte, men her fungerte den fint. Det den gjør er å kalle funksjonen jeg spesifiserer (lambda-uttrykket) for hvert element i listen(e) (to lister i dette tilfellet), men mapc returnerer så bare den første orginale listen, helt uendret. Det vil si at channels flyter videre ned til neste steg, hvor jeg ber om resultatene.
Med denne løsningen ser vi en klar forbedring av kjøretiden. 100 millioner tall prosesseres nå på 21,2 sekunder, en forbedring på 68%. Med teoretisk optimal parallelliseirng over fire kjerner skulle vi forvente noe nærmere 16,7 sekunder, men sånn fungerer det ikke helt i praksis.
Kanaler er kult og anvendelig, men lparallel tilbyr også noen andre abstraksjoner. En av dem er futures: "Fremtidige verdier". Vi kan opprette en future ved å wrappe Lisp-uttrykk (ett eller flere) i makroen future:
(defvar foo (future (+ 1 2 3 4)))
Summeringen vil nå bli utført i en ny tråd. For å hente ut verdien (eller vente på den til den er tilgjengelig) bruker vi force:
(force foo)
==> 10
Nå kan vi lage en tredje versjon av count-twos som bruker dette: Vi splitter opp oppgaven som før, lager en future for hver del, kaller force på hver av dem, og summerer sammen:
(defun count-twos-futures (start end &key (threads 4))
(->> (split-range threads start end)
(mapcar (lambda (piece)
(future (count-twos (car piece)
(cdr piece)))))
(mapcar #'force)
(reduce #'+)))
Sammenligner du med den som brukte kanaler så ser du at det ble enklere med futures.
Men lparallel har mer; pakken tilbyr også paralleliserte versjoner av en rekke mappingfunksjoner. MapReduce er jo et kjent konsept som sier at mapping alltid kan gjøres i parallell.
Så la oss lage enda en versjon av count-twos hvor det egentlig ser ut som om vi gjør alt sammen sekvensielt med vanlig Common Lisp, men hvor vi bytter ut mapcar med pmapcar:
(defun count-twos-pmap (start end &key (threads 4))
(->> (split-range threads start end)
(pmapcar (lambda (piece)
(count-twos (car piece)
(cdr piece))))
(reduce #'+)))
Det var jo en ytterligere forbedring. Og det fine er at ytelsen til alle de tre parallelle versjonene vi har laget er helt identisk! Her gjør vi ingen kjøretids-tradeoff, og kan velge fritt de abstraksjonene som gjør koden vår enklest å lese/skrive.
Av og til er antall CPU-kjerner ikke nok, og vi skulle hatt en enkel og tilsvarende måte å spre jobbene ut over flere maskiner. Frykt ikke - til det har vi pakken lfarm.
lfarm gjenbruker samme API som lparallel, men i stedet for å distribuere jobber i en thread pool så distribuerer den jobbene over et sett med servere.
I skjermdumpen nedenfor ser du tre terminaler. I de to nederste terminalene starter jeg opp en lfarm server (på samme maskin, men det hadde det altså ikke behøvd å være). I den første terminalen registrerer jeg de to serverne i *kernel*, og så bruker jeg pmapcar til å distribuere seks jobber.
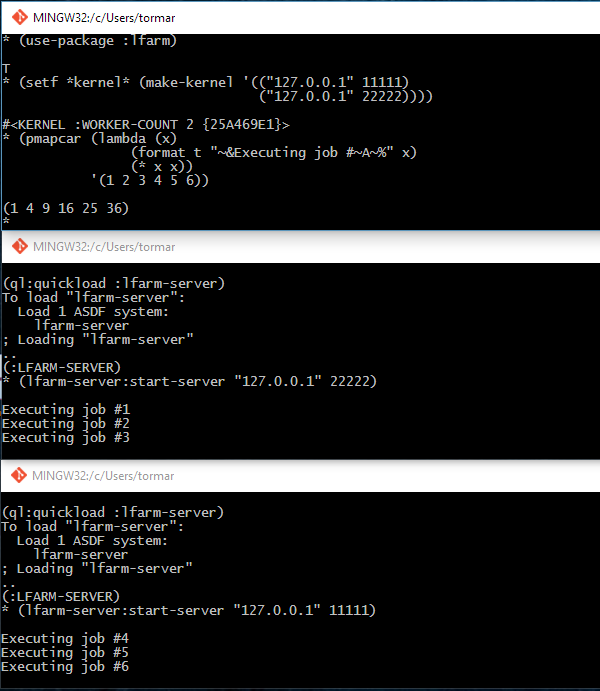
Kult? I alle fall er det enkelt.
Du har sett hvordan lparallel tilbyr en rekke abstraksjoner for parallellisering, og hvordan man i beste fall kan gå fra sekvensiell kode til parallell kode ved å bare tilføre ett eneste tegn (p). Og så har du sett at ved å inkludere et annet biblotek og endre litt på setupen så kan vi gå fra å distribuere jobber over tråder til å distribuere dem over flere maskiner.
Ingenting av dette var nyttig for å løse Knowit sin juleutfordring, men de fikk meg på sporet av noe som både var gøy og interessant.
Og slik ble det kun 111 dager igjen til Julaften. I binærtall da altså ;)