fredag 7. desember 2012 Julekalender Arkitektur BDD
Jeg ble kjent med Svein Arne Ackenhausen da jeg ble en del av programkommiteen for Norwegian Developers Conference. Under ser du ham i jam session med Carl Franklin fra .NET Rocks!
Svein Arne har bidratt til årets kalender med en tankevekkende artikkel – den er lang, men bør leses. Den har potensiale til å gi mang en utvikler dårlig samvittighet.

Hvem er du?
Trommis som byttet ut noter med kode og bandet med et konsulentfirma.
Hva er jobben din?
Driver et lite konsulentfirma ved navn Contango Consulting AS hvor jeg skriver kode for de som måtte ønske det.
Hva kan du?
Er blitt ganske flink til å se på programmering forbi programmeringsspråkene.
Hva liker du best med yrket ditt?
Følelsen av å ha skapt noe som faktisk er til nytte for andre.
Når jeg hører Dan North snakke om BDD er det som om alle brikkene faller på plass. Dette er hva software utvikling handler om. Strukturering av språk og kommunikasjonsform hjelper oss til å definere problemene vi prøver å løse. Når vi forstår problemet er det også en mulighet for at vi klarer å løse det. Spol frem 6-12 måneder og vi har akkurat det produktet kunden alltid har drømt om. Vel kanskje ikke men det er sånn vi ønsker å se på det.
Det BDD har lyktes med er å bidra med et sterkere fokus på å mer presist definere hva systemet gjør. Vi kommuniserer, vi skriver Given When Then (GWT) tekster (jeg sier bevisst ikke tester) sammen med beslutningstakerne. Vi lærer oss å forstå og utvikle konseptene i produktet. Dette er veldig bra! Vårt yrke har lenge hatt et for teknisk fokus. Vi «teknifiserer» problemet i et forsøk på å enklere kunne løse det teknisk. Arkitekturen, et pyramidisk sett med bokser (lag delt arkitektur) / et veldefinert sett med løkringer (onion architecture) osv. Vi får alle et bilde i hodet når vi tenker på arkitektur. For eksempel et ark bestående av piler og bokser. Faktum er at vi skal løse IKKE-TEKNISKE problemer ved hjelp av teknologi. Som tekniske kvinner og menn er vi blitt nødt til å innse at teknologien kommer i andre rekke i forhold til problemet vi prøver å løse.
La oss gjøre et lite sammendrag:
Som jeg begynte med er det en følelse av noe nesten magisk når Dan North snakker om BDD. Når jeg ser hvordan BDD adopteres i praktisk bruk klarer jeg sjelden å beholde den følelsen. Det virker på meg som om vi mister noe på veien fra konsept til praksis. Hvis du kjenner deg igjen i og er enig i de tre punktene over så gjør følgende: Tenk tilbake på prosjektene du har vært med på å utvikle. Se for deg kun arkitekturen.
Ok, så softwareproduktet kan defineres som summen av behaviours. Implementasjonen av en spesifikk behaviour er en konsekvens av behaviouren. Det betyr at den utfører de nødvendige stegene for å tilfredsstille behaviouren. Arkitekturen er da summen av alle implementerte behaviours. Altså Behaviours -> Implementasjoner -> Arkitektur. HVORFOR KAN JEG DA IKKE FORSTÅ HVA PRODUKTET GJØR UT I FRA ARKITEKTUREN??
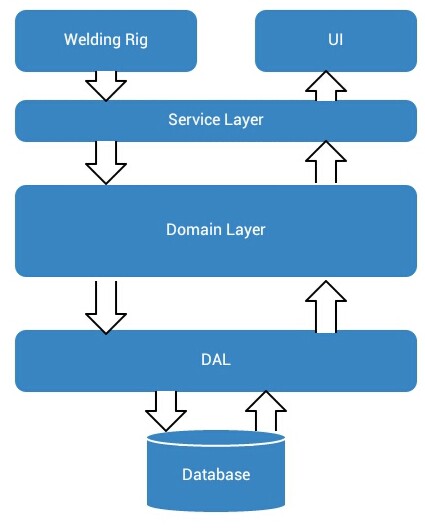
Som oftest når jeg ser et arkitekturdokument ser jeg noe som beskriver en lagdeling som vist på bildet under. I tillegg til dette lagdelingsbildet kommer et massivt databaseskjema som er beskrevet ned til hver minste detalj. Vi sprinkler på litt tekst for å forklare noen deler av arkitekturen bedre og voila! her har vi arkitekturen vår.
Ok, dette var en sterk forenkling av det hele, men jeg håper du forstår tanken. Vanligvis ser jeg GWT-tekster implementert som kjørbare tester. Det er forsåvidt bra. Tester er en god ting!
Problemet er bare at arkitekturen som beskrevet over representeres ikke som et resultat av Behaviours -> Implementasjoner -> Arkitektur. Den er mer et koderammeverk hvor vi kan dele hver behaviour inn i en UI del, en tjeneste del, en domene del og en data del. Deretter tar vi hver av delene og implementerer de der de hører hjemme. Vi har altså sett på behaviouren, teknifisert den inn i UI, tjeneste, domene og data så den passer inn i en forhåndsdefinert lagdelingsstruktur.
Resultatet blir at vi distanserer implementasjonen fra hva produktet faktisk skal gjøre. Dette leder igjen til at vi tar en god del beslutninger på helt feil grunnlag.
Men la oss først gå tilbake til BDD i praksis. I og med at vi har distansert implementasjonen fra behaviours er vi nødt til å abstrahere implementasjonen fra GWT-tekstene når vi gjør de om til eksekverbare spesifikasjoner. Resultatet blir dette:
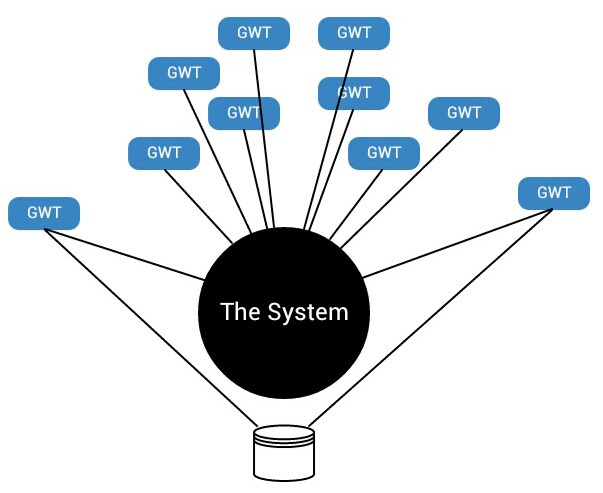
Grunnet at det ikke er noen klar relasjon mellom implementasjon og spesifikasjon ender vi opp med et stort sett med systemtester rundt en blackbox. Den eneste måten vi kan teste en blackbox på er igjennom systemtester. Systemtester er som vi vet veldig skjøre, veldig avhenginge av miljø, veldig tunge å vedlikeholde og generelt sett veldig utsatte for feil. En test man endrer oftere enn koden den tester har også høyere risiko for feil enn koden den prøver å verifisere. Altså faller den på sin egen urimelighet.
Vi var lenge enige om at systemtester var et nødvendig onde. Vi trengte noen av dem men vi holdt antallet så lavt som mulig fordi vi visste hva bakdelene med dem var. Jeg vil gå så langt som å si at et stort antall systemtester ofte er en code smell. Det tyder på at det underliggende systemet er en blackbox.
Hvordan ble systemet en blackbox? Hva gjorde at implementasjonen ikke ble til som en konsekvens av behavioren? Jeg tror mye av det ligger i hvordan vi tradisjonelt sett tenker på arkitektur. Tradisjonelle arkitekturer legger ofte føringer på hvordan kode skal implementeres i hvert lag. Dette betyr at vi tilpasser behaviouren til teknologien og ikke motsatt.
Et godt eksempel på akkurat dette er måten vi implementerer det vi kaller data-laget på. For det første ser jeg nesten aldri noe som kan kalles et datalag. Et lag er en absolutt separasjon. Et lag eksponerer ikke sin interne state. Det vil si at i et datalag kan ikke unit of work/transaksjonener eksponeres. Med det er vi inne på på noe veldig essensielt. Behovet vi har for transaksjoner og unit of works er grunnen til at ikke implementasjonen blir til som et resultat av behaviouren.
Så hvorfor trenger vi egentlig konseptet transaksjon utenfor persisteringslogikken? En generisk unit of work / transaksjon er noe vi trenger når vi ikke vet hva som er resultatet av et funksjonskall. Det vil si, vi starter en unit of work, kaller en overordnet metode som utfører en behaviour med alt det den måtte ville endre og til slutt committer unit of work. Realiteten er følgende: Vi vet ikke hva denne behaviouren gjorde. Hva den nå enn gjorde så ble alle endringer lagret et eller annet sted når vi committet.
Vi har med det distansert oss fra hva resultatet av behviouren er. Selve essensen i problemet vi prøver å løse forsvinner i "hva som nå enn ble committet".
Hadde vi satt oss ned og funnet ut akkurat hva resultatet av behaviouren er kunne vi i stedet sagt at funksjonen vi kaller returnerer resultatet av behaviouren. Det gir oss en klar input og en definert output. Det kan trygt testes! Vi vil da separere mellom det å utføre behaviouren og det å persistere eventuell resulterende state. Dette er en veldig viktig distinksjon.
Toppnivå-funksjonen vi vanligvis kaller innenfor en unit of work kan da isteden returnere resultatet av behaviouren. Det returnerte resultatet kan sendes videre til noe som håndterer persistering. Innenfor funksjonalitet fokusert rundt ren persistering er det helt naturlig å håndtere eventuelle transaksjoner. Dette er relatert til det Greg Young og Udi Dahan snakker om i CQRS når de nevner «transaction per aggregate». Ved å gjøre implementasjonen eksplisitt har vi kunnet fjerne behovet for unit of works. I stedet for å bygge systemet rundt en generisk persisteringsplatform fokuserer vi heller på persistering som direkte relatert til behaviouren. Det vil si at vi kan oppfylle punkt to over: «Den tekniske løsningen er et resultat av og kommer derfor i andre rekke i forhold til funksjonaliteten».
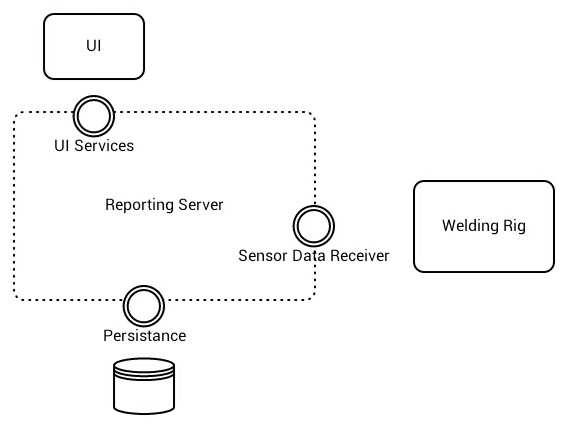
Det vi definerer inn i det vi kaller lagdeling er en liten del av arkitekturen men det er ikke arkitekturen. Hva er det da?
Dette er min definisjon. Jeg velger å heller notere punkter istedenfor lag som vist over. Punktene definerer hovedabstraksjonene i systemet. Transport-punkter en behaviour kan bevege seg imellom. For å få noen nytte av transportkartet må det knyttes opp mot selve behaviourene. La oss si at en av behaviourene i dette systemet er live rapportering av varme i UI’et. Vi kan da definere opp stegene i behaviouren som i bildet under.
Ved å representere hovedabstraksjoner som punkter har vi ikke lagt føringer på hvordan en behaviour skal implementeres, bare hvilke stopp reiseruten involverer. Vi er derfor frie til å definere implementasjonen av behaviouren på den måten som er best egnet.
En behaviour kan ofte sammenlignes med en funksjonell kjede. Man starter kjeden med et sett med data (parametere) man sender med det første funksjonskallet. Deretter igjennom flere steg transporterer, transformerer og beriker vi den initielle dataen. Når vi kommer til det siste steget i behaviouren sitter man med et sett med data som representerer konklusjonen av hva behaviouren er ment å oppnå.
Normen pr i dag er i stedet å lage en generisk arkitektur som teknisk definerer hvordan alle behaviours skal se ut. Vi definerer for eksempel at alle kall skal komme igjennom service laget. Deretter skal domeneklasser implementeres ut i fra n tekniske guide lines. Datalaget har selvfølgelig også sterke føringer på hvordan det skal implementeres.
Ok, stop!
La oss i stedet si at en behaviour selv dikterer hvordan den skal implementeres. Vi vil da gå bort fra den vanlige "one size fits all"-tankegangen.
Tanken mange har er at et system er mer forståelig når alle behaviours er implementert på samme måte. Jeg forstår hvor vi vil med en slik tanke men vi klarer ikke å se hvor stort kompromisset er ved en slik løsning. Vi har lært oss til å tro at en slik løsning blir en mindre kompleks løsning fordi koden da vil se enhetlig ut. Problemet er: Det at koden ser enhetlig ut er irrelevant! Det er en missvisende trygghet!
Problemet enhetlig kode / kode som ser lik ut kan ha er best forklart ved å se på DRY prinsippet. DRY (don't repeat yourself) er kanskje den største fallgruven vi som utviklere kan havne i. Missforstå meg rett - DRY er en god ting når det er brukt riktig, men når det er brukt feil er det et masseødeleggelsesvåpen!
Når man snakker om DRY glemmer man ofte å nevnte kontekst. Uten kontekst ødelegger DRY mer enn det hjelper. På plassen etter å faktisk løse problemet produktet er ment å løse kommer stabilitet. Vi må derfor være sikre på at når vi endrer et sted i koden så ødelegger vi ikke noe annet.
Kode skal IKKE være DRY fra et teknisk perspektiv men fra et funksjonelt perspektiv. Hele tanken bak DRY er at man ikke skal ha duplisert kode. Når man endrer kode skal man vite at man kun trenger å endre ett sted. Nøkkelen til dette ligger i å vite hva som endres sammen. Endringer kommer fra stakeholders. Endringer er nesten alltid rettet mot en behaviour. Vi må kunne garantere for at vi kan gjøre endringer i en behaviour uten å ødelegge andre behaviours. Produktets evolusjon kan ikke holdes tilbake som et resultat av at vi er redde for å ende opp med et ustabilt produkt. Vi må
iverata stabilitet samtidig som vi lar produktet evolvere.
Vi må derfor avgrense DRY til å gjelde innenfor behaviours, ikke alt som ser teknisk likt ut. Behaviours kan ofte inneholde de samme konseptene. Det vil ikke si at når et delt konsept endres i den ene behaviouren så skal det automatisk endres i den andre. Vi vet at hvis vi tar på noe, ødelegger vi det. Det er bare sånn softwareutvikling er. Det som endres sammen deler samme kode og det er da mer forståelig at det ødelegges sammen ;) (bruk av plumbing og rammeverk er unntak).
La oss gå tilbake til problemet med "one size fits all"-arkitekturen. Denne typen implementasjon forutsetter også at alle behaviours er like. Hvis det er tilfellet er det verdiløs kode å skrive.
Se på Ruby on Rails. De har forstått at hvis applikasjonen din er ren CRUD så trenger du ikke skrive koden. Du kan i stedet generere den. Alle behaviours er bygget opp på samme måte: Hente data, endre data, lagre endringen. Med en gang det begynner å komme behaviours som ikke er CRUD ender vi isteden opp med et sammensurium hvor alt ser enhetlig ut. Det vil være det samme som om jeg forteller deg at den personen snakker italiensk men jeg kan ikke fortelle deg hva hun/han sier. Jeg forstår strukturen i språket men ikke innholdet. Dette er kompromisset vi tar ved å fokusere på at kode ser teknisk lik ut. Vi forstår at vi jobber med repositories, services, entiteter og units of work. Men vi har ingen anelse angående hva den gjør. Dette er et ENORMT kompromiss. Vi har allerede sagt oss enige i at behaviours er viktigere enn implementasjonen som er et resultat av behaviouren. Likevel har vi endt opp med å vurdere lesbarheten av de tekniske konseptene høyere enn forståelsen av behaviours.
Software er ment å endre seg. Arkitekturen er ment å endre seg. Med mindre du har klart å lage et perfekt under av et produkt på første forsøk kommer systemet til å endre seg. Så lenge det endrer seg betyr det at vi forstår mer om problemet vi prøver å løse. Vi perfeksjonerer produktet mot å løse stakeholders problem på best mulig måte.
For kontinuerlig å kunne forbedre produktet må det være optimalisert for endringer. Det er derfor kritisk at behaviours er implementert i isolasjon. Som nevnt tidligere er endringer nesten alltid relatert til en behaviour. For å kunne ivareta det må vi sørge for at koden er nærmere knyttet til selve problemet.
BDD har satt oss på rett spor. Vi må bare ta det videre inn i implementasjonen og arkitekturen. Et for sterkt fokus på den teniske strukturen av softwarearkitektur vil selv med gode hensikter ofte lede til en stor andel “accidental complexity”. Kompleksitet som er der fordi distansen mellom den funksjonelle definisjonen av systemet og den tekniske definisjonen er for stor. Å krympe/eliminere denne distansen er hva BDD skulle gjort med arkitekturen vår!